elasticsearch 安装
环境配置
linux环境配置
创建elk用户并设置elk用户的密码
elasticsearch默认不能在root用户下运行,所以需新创建一个elk用户,具体操作如下。
2
3
$ useradd -g elk -m elk
$ passwd elk
设置linux环境参数
修改limits.conf配置文件
limits.conf是会话级别,退出会话重新登录需改即可生效。
1
2
3
4
5$ vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096修改20-nproc.conf配置文件
某些版本的linux的max user processes配置来源是20-nproc.conf,还需修改20-nproc.conf(centos6 是90-nproc.conf)。
1
2$ vim /etc/security/limits.d/20-nproc.conf
* soft nproc 4096设置sysctl.conf配置文件
1
2
3$ vim /etc/sysctl.conf
vm.max_map_count=655360
$ sysctl -p
java环境配置
elasticsearch 6.5.*需要jdk版本1.8,如果系统中没有jdk或者是jdk版本不符合要求,那么需要安装jdk,以下是在elk用户下安装jdk的示例。
2
3
4
5
6
7
$ tar -xzvf jdk-8u192-linux-x64.tar.gz
$ mv jdk1.8.0_192/ jdk
$ vi ~/.bash_profile
export JAVA_HOME=/home/elk/soft/jdk
PATH=$PATH:$HOME/.local/bin:$HOME/bin:/home/elk/soft/jdk/bin
$ source .bash_profile
elasticsearch安装
1 | $ tar -xzvf elasticsearch-6.5.2.tar.gz |
kibana安装
1 | $ tar -xzvf kibana-6.5.2-linux-x86_64.tar.gz |
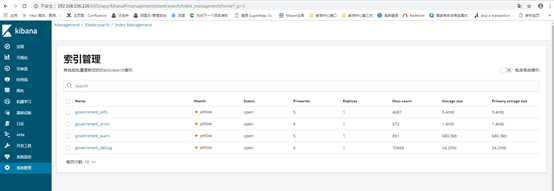
验证kibana是否安装成功,http://192.168.0.xxx:5601
kibana汉化
Kibana_Hanization汉化需要python2.7环境,一般安装linux都会自带python2.7环境
2
3
4
$ #执行下面命令汉化kibana
$ cd Kibana_Hanization-master/
$ python main.py /path_for_kibana/kibana-6.5.2-linux-x86_64/
kafka的搭建
kafka安装
1 | $ tar -xvzf kafka_2.11-2.0.0.tar.gz -C /usr/local/elk/ |
kafka测试
1 | $ #执行下面的命令创建一个topic,名称为“testTopic”: |
logstash安装
1 | $ tar -xvzf logstash-6.5.2.tar.gz -C /usr/local/elk/ |
filebeat安装
1 | $ tar -xvzf filebeat-6.5.3-linux-x86_64.tar.gz -C /usr/local/elk/ |
logstash 配置示例
1 | input { |
logstash jdbc配置示例
1 | input{ |
elasticsearch 集群配置
elasticsearch.yml文件配置示例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: logdig
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node3
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 192.168.106.178
#
# Set a custom port for HTTP:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["192.168.106.xxx", "192.168.106.yyy","192.168.106.zzz"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
discovery.zen.minimum_master_nodes: 2
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
在这3台服务器分别启动,命令如下:
elasticsearch使用示例【集群模式下】
1 | $ curl 192.168.106.xxx:9200/_cat/shards |