网络
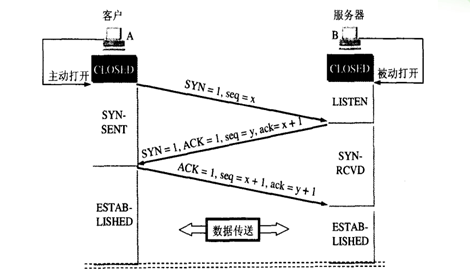
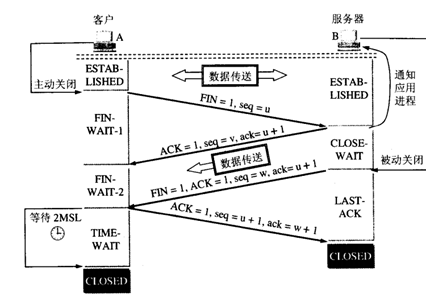
tcp握手
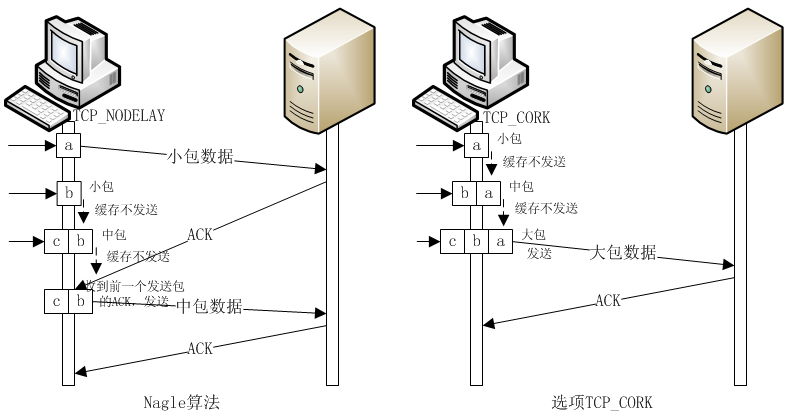
tcp_cork
sendfile
读取文件并socket传输的普通过程
- read(file,tmp_buf, len);
write(socket,tmp_buf, len); - 系统调用 read()产生一个上下文切换,从 user mode 切换到 kernel mode,然后 DMA 执行拷贝,把文件数据从硬盘读到一个 kernel buffer 里。
- 数据从 kernel buffer拷贝到 user buffer,然后系统调用 read() 返回,这时又产生一个上下文切换,从kernel mode 切换到 user mode。
- 系统调用write()产生一个上下文切换,从 user mode切换到 kernel mode,然后把步骤2读到 user buffer的数据拷贝到 kernel buffer,不过这次是个不同的 kernel buffer,这个 buffer和 socket相关联。
- 系统调用 write()返回,产生一个上下文切换,从 kernel mode 切换到 user mode ,然后 DMA 从 kernel buffer拷贝数据到协议栈。
sendfile的协议栈传输过程
- sendfile(socket,file, len);
- 系统调用sendfile()通过 DMA把硬盘数据拷贝到 kernel buffer,然后数据被 kernel直接拷贝到另外一个与 socket相关的 kernel buffer。这里没有 user mode和 kernel mode之间的切换,在 kernel中直接完成了从一个 buffer到另一个 buffer的拷贝。
- DMA 把数据从 kernelbuffer 直接拷贝给协议栈,没有切换,也不需要数据从 user mode 拷贝到 kernel mode,因为数据就在 kernel 里。
适用场景
sendfile 是将 in_fd 的内容发送到 out_fd 。而 in_fd 不能是 socket , 也就是只能文件句柄。 所以当 Nginx 是一个静态文件服务器的时候,开启 SENDFILE 配置项能大大提高 Nginx 的性能。 但是当 Nginx 是作为一个反向代理来使用的时候,SENDFILE 则没什么用了,因为 Nginx 是反向代理的时候。 in_fd 就不是文件句柄而是 socket,此时就不符合 sendfile 函数的参数要求了。
accept_mutex
- 当一个新连接到达时,如果激活了accept_mutex,那么多个Worker将以串行方式来处理,其中有一个Worker会被唤醒,其他的Worker继续保持休眠状态;如果没有激活accept_mutex,那么所有的Worker都会被唤醒,不过只有一个Worker能获取新连接,其它的Worker会重新进入休眠状态,这就是「惊群问题」。
- OS may wake all processes waiting on accept() and select(), this is called thundering herd problem. This is a problem if you have a lot of workers as in Apache (hundreds and more), but this insensible if you have just several workers as nginx usually has. Therefore turning accept_mutex off is as scheduling incoming connection by OS via select/kqueue/epoll/etc (but not accept()).
multi_accept
- 在Nginx获得有新连接的通知之后,接受尽可能多的连接。
tcp_nopush
Enables or disables the use of the TCP_NOPUSH socket option on FreeBSD) or the TCP_CORK socket option on Linux. The options are enabled only when sendfile is used. Enabling the option allows
- sending the response header and the beginning of a file in one packet, on Linux and FreeBSD 4.*;
- sending a file in full packets.
- 在nginx中,tcp_nopush配置与tcp_nodelay“互斥”。它可以配置一次发送数据包的大小。也就是说,数据包累积到一定大小后就发送。
- 在nginx中tcp_nopush必须和sendfile配合使用。
tcp_nodelay
这个选项的作用就是禁用 Nagle’s Algorithm,默认开启。1
2
3
4
5
6
7
8
9
10
11
12#nagle algorithm
if there is new data to send
if the window size >= MSS and available data is >= MSS
send complete MSS segment now
else
if there is unconfirmed data still in the pipe
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
可以看到,当待发送的数据比 MSS 小的时候(外层的 else 分支),还要再判断 时候还有未确认的数据。只有当管道里还有未确认数据的时候才会进入缓冲区, 等待 Ack。
所以发送端发送的第一个 write 是不会被缓冲起来,而是立刻发送的(进入内层 的else 分支),这时接收端收到对应的数据,但它还期待更多数据才进行处理, 所以不会往回发送数据,因此也没机会把 Ack 给带回去,根据Delayed Ack 机制, 这个 Ack 会被 Hold 住。这时发送端发送第二个包,而队列里还有未确认的数据 包,所以进入了内层 if 的 then 分支,这个 packet 会被缓冲起来。此时,发 送端在等待接收端的 Ack;接收端则在 Delay 这个 Ack,所以都在等待,直到接 收端 Deplayed Ack 超时(40ms),此 Ack 被发送回去,发送端缓冲的这个 packet 才会被真正送到接收端,从而继续下去。
再看我上面的 strace 记录也能发现端倪,因为设计的一些不足,我没能做到把 短小的 HTTP Body 连同 HTTP Headers 一起发送出去,而是分开成两次调用实 现的,之后进入 epoll_wait 等待下一个 Request 被发送过来(相当于阻塞模 型里直接 read)。正好是 write-write-read 的模式。
那么 write-read-write-read 会不会出问题呢?维基百科上的解释是不会。
Delayed Ack 机制
keepalive_timeout
这个参数不是tcp的keepalive,是程序的keepalive,处理完业务后会等待一段时间再关闭连接.
net.ipv4.tcp_tw_recycle
net.ipv4.tcp_tw_recycle = {0|1} 是否启用timewait快速回收;注意:开启此功能在NAT环境下可能会出现严重的问题:因为TCP有一种行为,它可以缓存每个连接最新的时间戳,后续请求中如果时间戳小于缓存中的时间戳,即被视为无效并丢弃相应的请求报文;Linux是否启用这种行为取决于tcp_timestamp和tcp_tw_recycle,而前一个参数默认是启用的,所以启用后面的参数就会激活此功能; 因此,如果是NAT环境,安全起见,应该禁用tcp_tw_recycle。另一种解决方案:把tcp_timestamps设置为0,tcp_tw_recycle设置为1并不会如想象中奏效,因为一旦关闭了tcp_timestamps,那么即便打开了tcp_tw_recycle,后面的参数也没有效果。此时降低net.ipv4.tcp_max_tw_buckets的值就可以显著降低tw连接的数量了。对客户端和服务器同时起作用。
net.ipv4.tcp_tw_reuse
net.ipv4.tcp_tw_reuse = {0|1} 是否开启tw重用,即是否允许将TIME-WAIT sockets 用于新的TCP连接,就是数据结构不会收,只更改一下ip和port就继续使用。 只对客户端起作用,开启后客户端在1s内回收。
somaxconn
定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128,对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多。大的侦听队列对防止拒绝服务 DoS 攻击也会有所帮助。
net.core.netdev_max_backlog = 262144
每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目。
net.ipv4.tcp_max_syn_backlog = 262144
这个参数标示TCP三次握手建立阶段接受SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
MTU MSS
MTU: Maxitum Transmission Unit 最大传输单元
MSS: Maxitum Segment Size 最大分段大小
MSS就是TCP数据包每次能够传输的最大数据分段。为了达到最佳的传输效能TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes), 通讯双方会根据双方提供的MSS值得最小值确定为这次连接的最大MSS值。而一般以太网MTU都为1500, 所以在以太网中, 往往TCP MSS为1460。
滑动窗口与内核缓冲区的关系
- net.ipv4.tcp_rmem:这个参数定义了TCP接收缓冲(用于TCP接收滑动窗口)的最小值、默认值、最大值
- net.ipv4.tcp_wmem:这个参数定义了TCP发送缓冲(用于TCP发送滑动窗口)的最小值、默认值、最大值
- netdev_max_backlog:当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。这个参数表示队列的最大值
- rmem_default:这个参数表示内核套接字接收缓存区默认的大小
- wmem_default:这个参数表示内核套接字发送缓存区默认的大小
- rmem_max:这个参数表示内核套接字接收缓存区最大的大小
rmem_max:这个参数表示内核套接字接收缓存区最大的大小
对于发送数据来说,应用程序将数据拷贝到各自TCP发送缓冲区内(也就是发送滑动窗口),然后系统的所有TCP套接字上发送缓冲区(也就是发送滑动窗口)内的数据都将数据拷贝到内核发送缓冲区内,然后内核将内核缓冲区的数据经过网卡发送出去。TCP的发送/接受缓冲区(也就是发送/接受滑动窗口),是针对某一个具体的TCP连接来说的,每一个TCP连接都会有相应的滑动窗口,但是内核的发送/接受缓冲区是针对整个系统的,里面存放着整个系统的所有TCP连接的接收/发送的数据。